It's a good thing my choice is to confront the demon problem full-on, headstrong, because, if I had chosen otherwise, I couldn't even run from it with a car, as evidenced not only by the speed at which one can be seen traveling in a recently made video clip, but by their obsession with establishing a presence in every place and everything.
NOTE | One demon rally goes: "In every closet, under every bed!" Surprisingly, that's one of the least disturbing of all their rallying cries. The ones they gave to their people would chill you to the bone. It is a world sick with sin, let me tell you.
The video was made during my transit from an apartment to a car as I held my iPhone in my hand, the camera pointed behind me. In the portion of it shown below, you can see a demon orb racing around the corner of a building and then into the car in front of me:
Like a lot of orbs in the videos I've posted to this blog, distinguishing the orb from a lens flare is difficult without analyzing the flight path; plus, demon orbs make prodigious use of "environmental camouflage" when moving within viewing range of a human—a behavior well-documented by video and pics in hundreds of posts to this blog.
Clip provides tactical data for pending war against demons, demon people
What else is interesting about this particular clip is that it shows a slight decrease and flare of the orb as it crosses the path of the lamp attached to the building; it has been observed that entering and exiting "twilight zones," the borders created by shadow/light and weak light/strong light, require an adjustment of some kind on the part of a demon camouflaging using light and shadow. This is the first video I have that demonstrates that the required time to make the adjustment can be an impediment to motility; it is the second video proving that demons are affected by things we can touch and access [seeSCIENCE | Red demon orbs turn blue under extreme heat].
Other clips providing requisite context
The following posts show some of the most recent videos showing demons orbs like this one on the move or on the attack; they should be viewed in tandem with the clip above for context and reference:
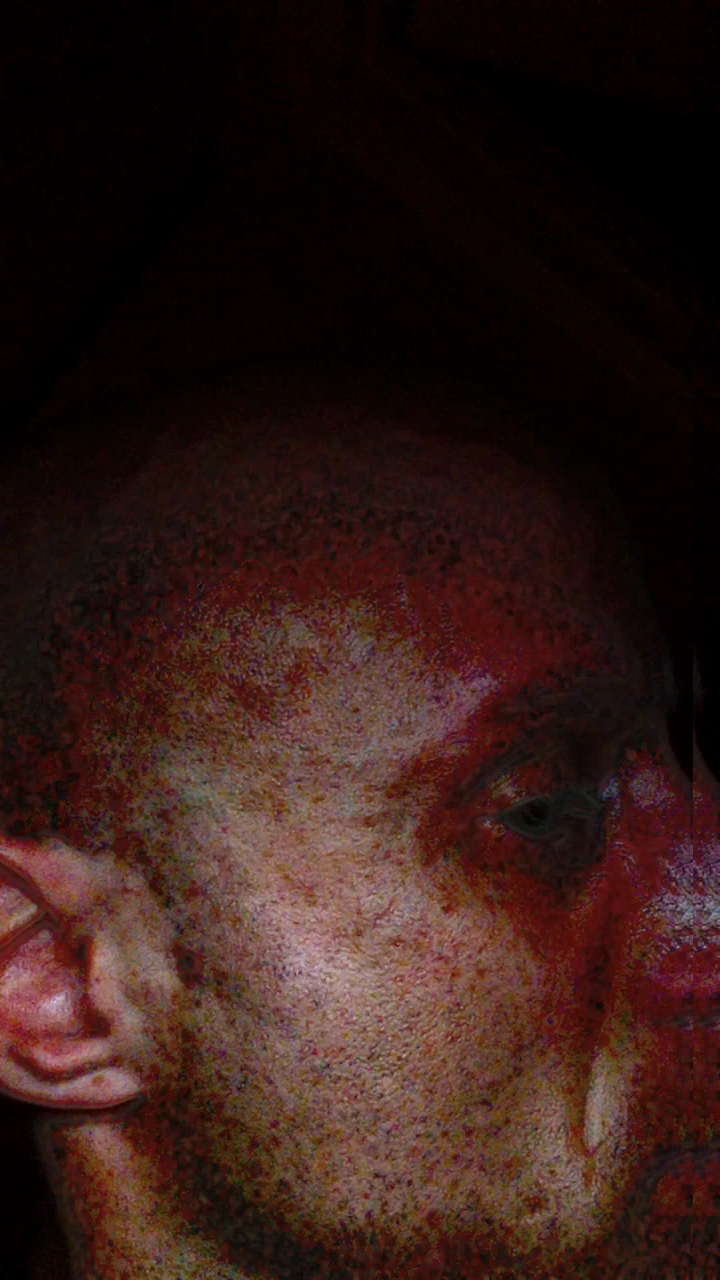
The following still frames were taken from a video made during a period of high demonic activity, shot with my iPad mini using a special imaging filter I developed to capture in digital media cloaked (invisible) and chroma-saturated (noise-emittingd) objects and entities on surfaces, especially, the face:
The video was processed in real-time by a version of my Standard Deviation imaging filter, which reveals cloaked (invisible) entities and other matter on the surface of skin, and which plugs into the sample app provided to iOS developers by Apple that I customized, as well as any other iOS app that supports Core Image filters
There are several sets of these still frames, grouped according to the particular additional imaging filter (also of my own making) applied to them subsequent to making the video on my iPhone. The multiple sets of still frames are intended to demonstrate just how many levels or layers on which demonic activity can be found, in that each filtered set shows details and objects not found in the other sets.
Still frames were post-processed using my Prewitt Kernel filter, a Photo Editing Extension for the iPhone, equalizing the histogram and stretching the contrast for one set (right), but not the other (left); note how much more is revealed by equalization and stretch, even though the same filter was applied to both
Providing images such as these, which show my face being disassembled in the ether, and for no other purpose than cruelty—a cruelty that has, is and will continue to progressively disfigure and cause pain in my face, neck and head—serves more than just public interest: they also prove that anyone with a cellphone (iPhone) can see the unseen given the necessary and correct imaging filters for doing so. Not only that, but they also prove that this is possible right now, and within everyone's reach, thanks, in part, to a bevy of image-processing resources available online, as well as Apple's developer tools and support.
Xcode is a free dowload from Apple's developer website, and is well-supported by a huge number of developers world-wide
Like a doctor and his X-rays, you should also retreat to a darkened room when viewing them (HD displays only). The optimal viewing size is about 66% of the original, even though, ironically, these images are intended to be inspected as close range.
Processed by my Prewitt Kernel
imaging filter, using my iPhone
Here are the originals:
The original still frames from a video made with an iPhone camera app now in development
Whereas using different filters reveal different things, equalizing the histogram and stretching the contrast of images processed by the same filter also reveals different things. The following set of still frames were processed by the Prewitt Kernel, the same filter used to process the first set of still frames in this post; and, while they are highly distorted compared to those in that set, they reveal much, much more:
Like the first set of still frames
(at the top of this post),
these were post-processed by
my Prewitt Kernel imaging filter,
but with histogram equalization and
contrast stretching applied
[note that their are actual holes where it looks like there are holes...]
A quick note about this post before you read it...
Here's what one blog author wrote about the task I am currently applied to—specifically, what it is I am trying to do, what I am doing right now, what it takes to get to the goal, and the hurdles I face.
On the multiplicity of possible tools:
There are dozens of different kernels which produce many different feature maps, e.g. which sharpen the image (more details), or which blur the image (less details), and each feature map may help our algorithm to do better on its task (details, like 3 instead of 2 buttons on your jacket might be important).
Just like the quote says, even the slightest adjustments to a kernel can make a huge difference in two otherwise identical images, like this one
Alternating the kernel divisor between just -1 to 1 revealed a sucker demon (white, string-like entity above right nostril) on the end of my nose in one rendering of a still, but not in another rendering of the same still frame
The type of work I am engaged in:
Using this kind of procedure — taking inputs, transforming inputs and feeding the transformed inputs to an algorithm — is called feature engineering. Feature engineering is very difficult, and there are little resources which help you to learn this skill. In consequence, there are very few people which can apply feature engineering skillfully to a wide range of tasks.
The complexity of the task:
Feature engineering is so difficult because for each type of data and each type of problem, different features do well: Knowledge of feature engineering for image tasks will be quite useless for time series data; and even if we have two similar image tasks, it will not be easy to engineer good features because the objects in the images also determine what will work and what will not. It takes a lot of experience to get all of this right. So feature engineering is very difficult and you have to start from scratch for each new task in order to do well.
NOTE | Apparently, they have the tools, skills and experience to make that happen, and introduced this fact and their intentions for 15 minutes somewhere during their diatribe on their power and anger and hatred for me during my shower today.
Processing images made during periods of high demonic activity using an edge detection kernel/convolution filters will invariably uncover things you wouldn't see at any other time or with any other filter. There is activity at every level during such periods from sources as thin as a hair to as big as the sky. Edge detection filters are concerned with the former. A good edge detection filter will count the hairs on the head of a hair; an even better one will count those hairs at arms length.
NOTE | Read how they work at the end of this post, which also includes sample code for OpenGL ES and Objective-C programmers.
This post describes just such a filter, one based on the Prewitt Operator.
The smallest of details, literally
The Prewitt Operator brings out detail on the most minute level possible on imaging devices without specialized hardware (i.e., the iPhone), allowing you to search for the hardest-to-find hidden demons and to analyze otherwise blurry cloaked objects up-close and in-detail with accuracy limited only by your device's display, hence my platform choice for the initial distribution of my imaging filters [seeApple Retina HD Display].
It produces razor-sharp edges—too sharp for most lit-environments, requiring one to view most videos and images processed by this kernel viewable only in the dark; however, even given its penchant for pricy hardware and inconvenient (especially under the circumstances) viewing requirements, it is an indispensable tool for uncovering things that other filters don't, rendering super-fine surface detail from distances much farther away than most surface-analysis filters.
The following still frames from a recently made video prove the point; they show a man's claw-hand demonic weapon jabbing at me in super-fine detail:
Micro-fine detail in still frames showing motion...
The Prewitt Kernel dispenses with both the blur and the noise of these types of images and enhances detail at the same time, enabling the undulating nature some metals exhibit when demons run amok:
It's not because of the motion blur that makes the metal on the car look like it is dripping upwards; rather, it is because of motion that the undulation of the (temporarily) highly malleable metal can be seen
Occasionally, matter in a transitory state between cloaked and normal can be captured clearly without special image processing, as shown by the above image of a t-shirt being transformed and otherwise manipulated by its possessing demon [fromHow demons alter matter]; however, in most cases, filters are needed
Highlight demonic-activity "hot" spots
A welcome-but-unexpected perk of the Prewitt Kernel is what most photographers would call a disadvantage: chromatic aberration (color misalignment). The color in an image processed by this kernel should look black-and-white for the most part; however, in some parts, red, green and blue are misaligned, creating a rainbow in an otherwise cloudy sky. This is due to the effect of EMF radiation emitted by cloaked molecules on the CCD sensor in digital cameras and/or the effect that it has on light itself (probably the latter, mostly; the former usually results in color noise—not aberration).
That's a good thing, as higher EMF radiation levels go hand-in-hand with danger, particularly from angry demons who want to interact forcibly with normal matter or fire weapons. In the first series of images above and the video clip itself (below), note the red color to the man firing the weapon; he would not be that color—or at nearly that red—had he not been in battle mode, as the Voices Demons and their people say:
And, the original for comparison:
NOTE | The YouTube version of the clip and the clip as displayed on an iPhone 5 or 6 is a very, very different view.
Ideal photographic conditions
The ideal conditions under which the Prewitt Kernel imaging filter works best and/or the kinds of activity best captured by it are:
Lights (when the subject or activity is in daylight, even though, ironically, the media must be viewed in the dark, similar to a doctor examining X-rays)
Camera (when the torch is enabled and the camera held in close proximity to the subject or surface)
Action (when the camera or subject is in-motion)
Implementing the kernel and/or convolution
The Prewitt Operator was implemented by kernel and convolution in OpenGL ES 3.0 and Objective-C, respectively; the code for both are provided below.
OpenGL ES 3.0 (in Quartz Composer)
The OpenGL kernel version of the Prewitt Operator, as authored in Quartz Composer:
Prewitt Kernel (in Quartz Composer)
The code:
/*
A Core Image kernel routine that applies edge detection per the Prewitt Kernel.
The code finds the difference between the pixel values on either side (x-axis)
result = [result imageByCroppingToRect:cropRectLeft];
result = [CIFilterfilterWithName:@"CICrop"keysAndValues:@"inputImage", result, @"inputRectangle", cropRect, nil].outputImage;
result = [CIFilterfilterWithName:@"CIAreaMaximum"keysAndValues:@"inputImage", result, @"inputExtent", [CIVectorvectorWithX:0.0Y:0.0Z:result.extent.size.widthW:result.extent.size.height], nil].outputImage;
result = [result imageByCroppingToRect:cropRectLeft];
result = [CIFilterfilterWithName:@"CICrop"keysAndValues:@"inputImage", result, @"inputRectangle", cropRect, nil].outputImage;
return result;
About the Prewitt Operator, Core Image
Note that, as a convolution, the Prewitt Operator requires two passes: one for edge detection; one for edge direction. Also, Core Image requires the output of convolutions to be rendered to a new extent (or Core Graphics rectangle) in order to be visible. Finally, the micro-fine output from the Prewitt Operator was created by reducing the bias on both convolution matrix filters by half, and by inverting the results.